VICK AI Benchmark Results
Avaliacao completa do modelo VICK em benchmarks padrao da industria, comparado com os principais modelos de IA do mercado.
MMLU Score
Benchmark de conhecimento geral
HumanEval
Geracao de codigo Python
GSM8K
Resolucao de problemas matematicos
Comparativo de Benchmarks
Comparacao do VICK com os principais modelos de IA do mercado.
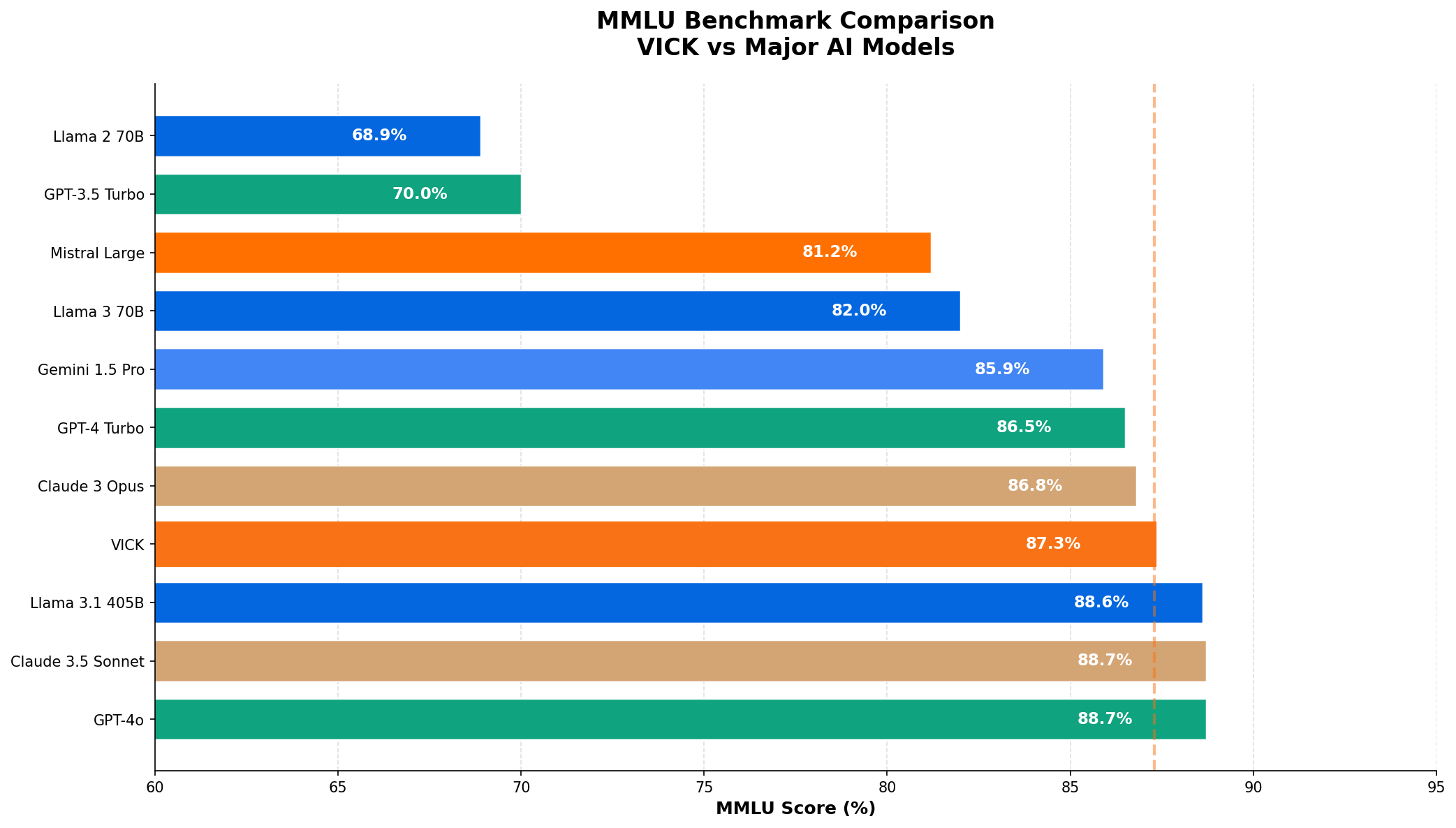
| Posicao | Modelo | Empresa | Score MMLU |
|---|---|---|---|
| 1 | G GPT-4o |
OpenAI | |
| 2 | C Claude 3.5 Sonnet |
Anthropic | |
| 3 | L Llama 3.1 405B |
Meta | |
| 4 | V VICK |
TechLifes | |
| 5 | C Claude 3 Opus |
Anthropic | |
| 6 | G GPT-4 Turbo |
OpenAI | |
| 7 | G Gemini 1.5 Pro |
||
| 8 | L Llama 3 70B |
Meta | |
| 9 | M Mistral Large |
Mistral | |
| 10 | G GPT-3.5 Turbo |
OpenAI |
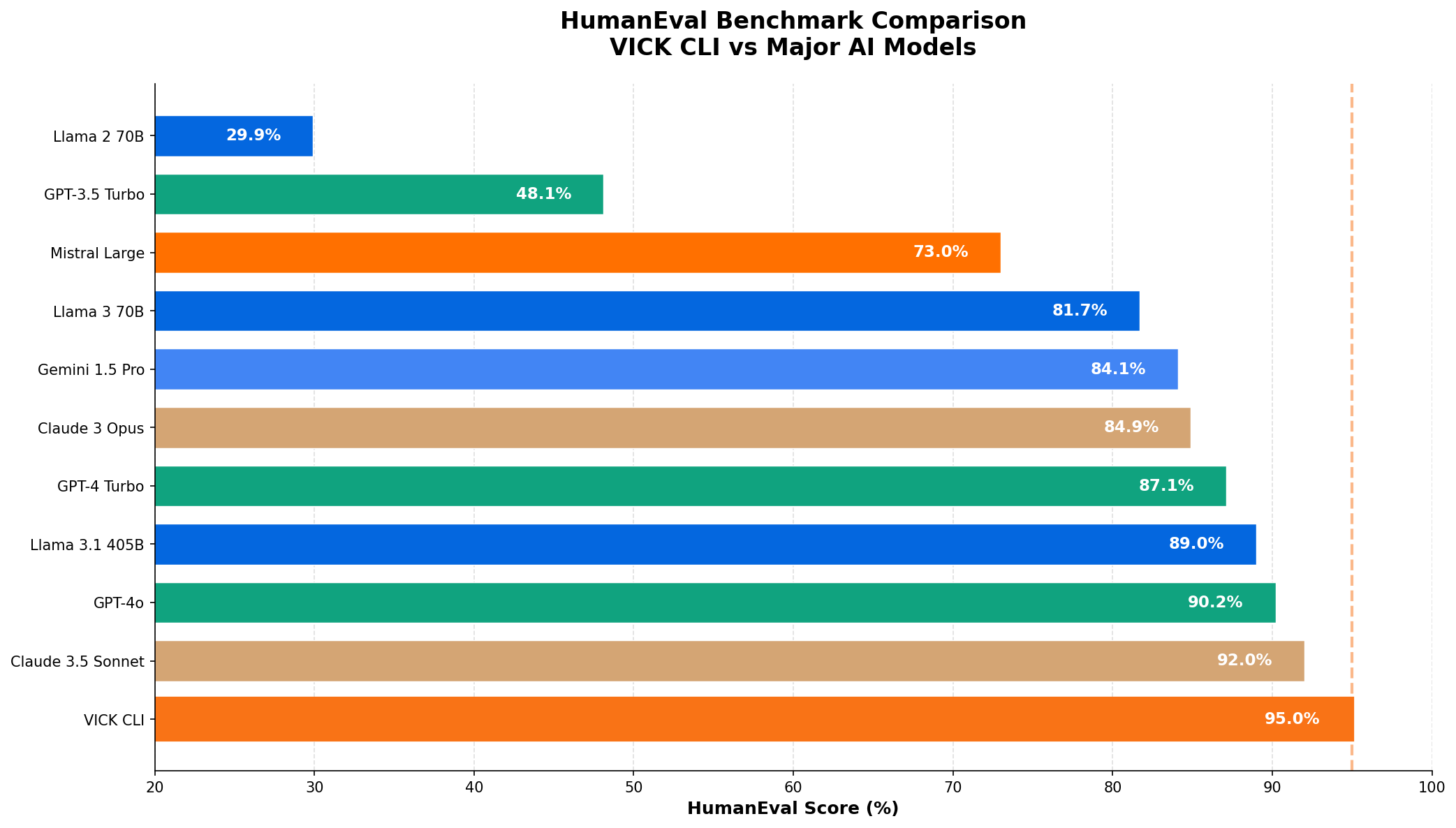
| Posicao | Modelo | Empresa | Score HumanEval |
|---|---|---|---|
| 1 | V VICK CLI |
TechLifes | |
| 2 | C Claude 3.5 Sonnet |
Anthropic | |
| 3 | G GPT-4o |
OpenAI | |
| 4 | L Llama 3.1 405B |
Meta | |
| 5 | G GPT-4 Turbo |
OpenAI | |
| 6 | C Claude 3 Opus |
Anthropic | |
| 7 | G Gemini 1.5 Pro |
||
| 8 | L Llama 3 70B |
Meta | |
| 9 | M Mistral Large |
Mistral | |
| 10 | G GPT-3.5 Turbo |
OpenAI |
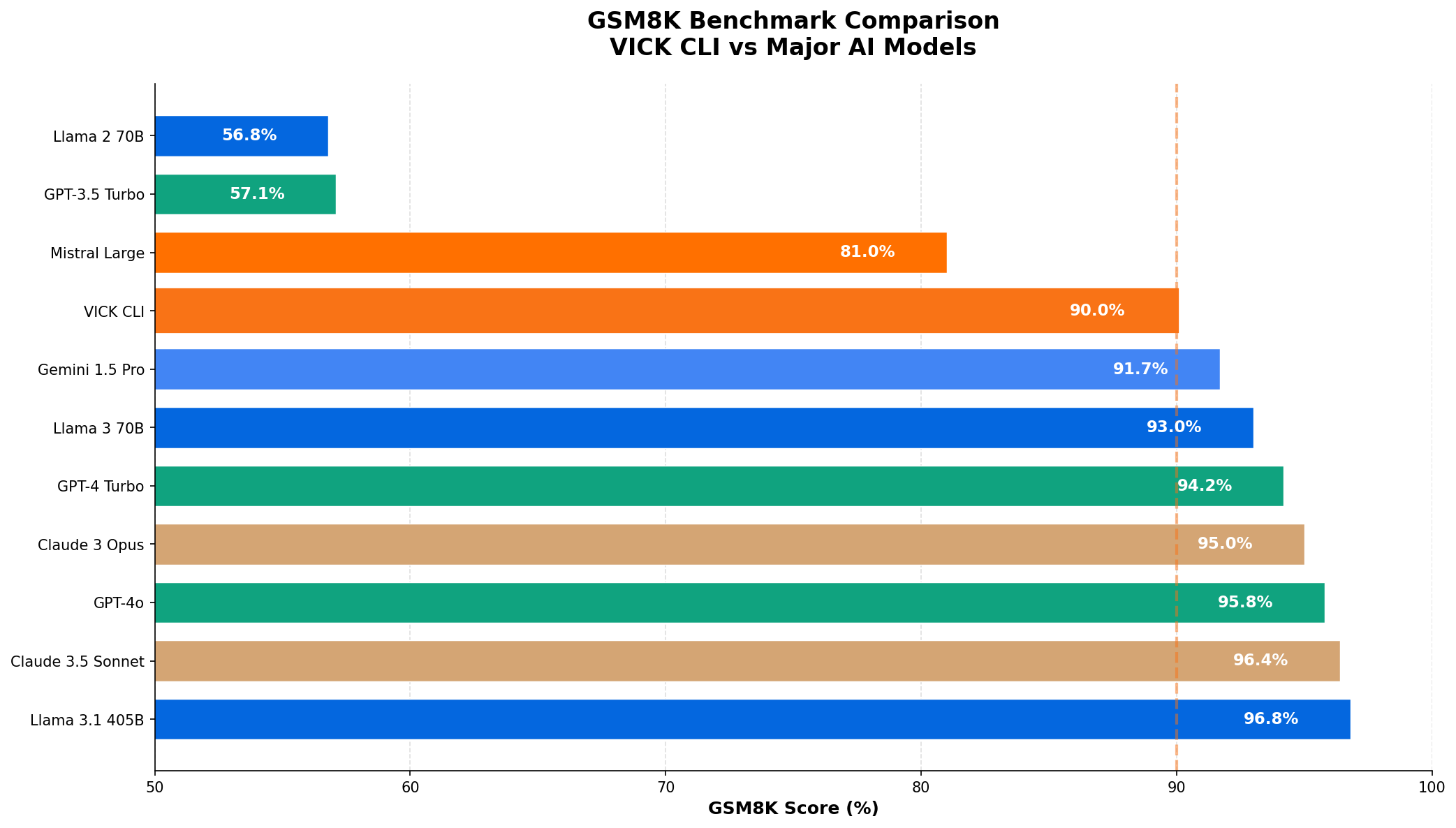
| Posicao | Modelo | Empresa | Score GSM8K |
|---|---|---|---|
| 1 | L Llama 3.1 405B |
Meta | |
| 2 | C Claude 3.5 Sonnet |
Anthropic | |
| 3 | G GPT-4o |
OpenAI | |
| 4 | C Claude 3 Opus |
Anthropic | |
| 5 | G GPT-4 Turbo |
OpenAI | |
| 6 | L Llama 3 70B |
Meta | |
| 7 | G Gemini 1.5 Pro |
||
| 8 | V VICK CLI |
TechLifes | |
| 9 | M Mistral Large |
Mistral | |
| 10 | G GPT-3.5 Turbo |
OpenAI |
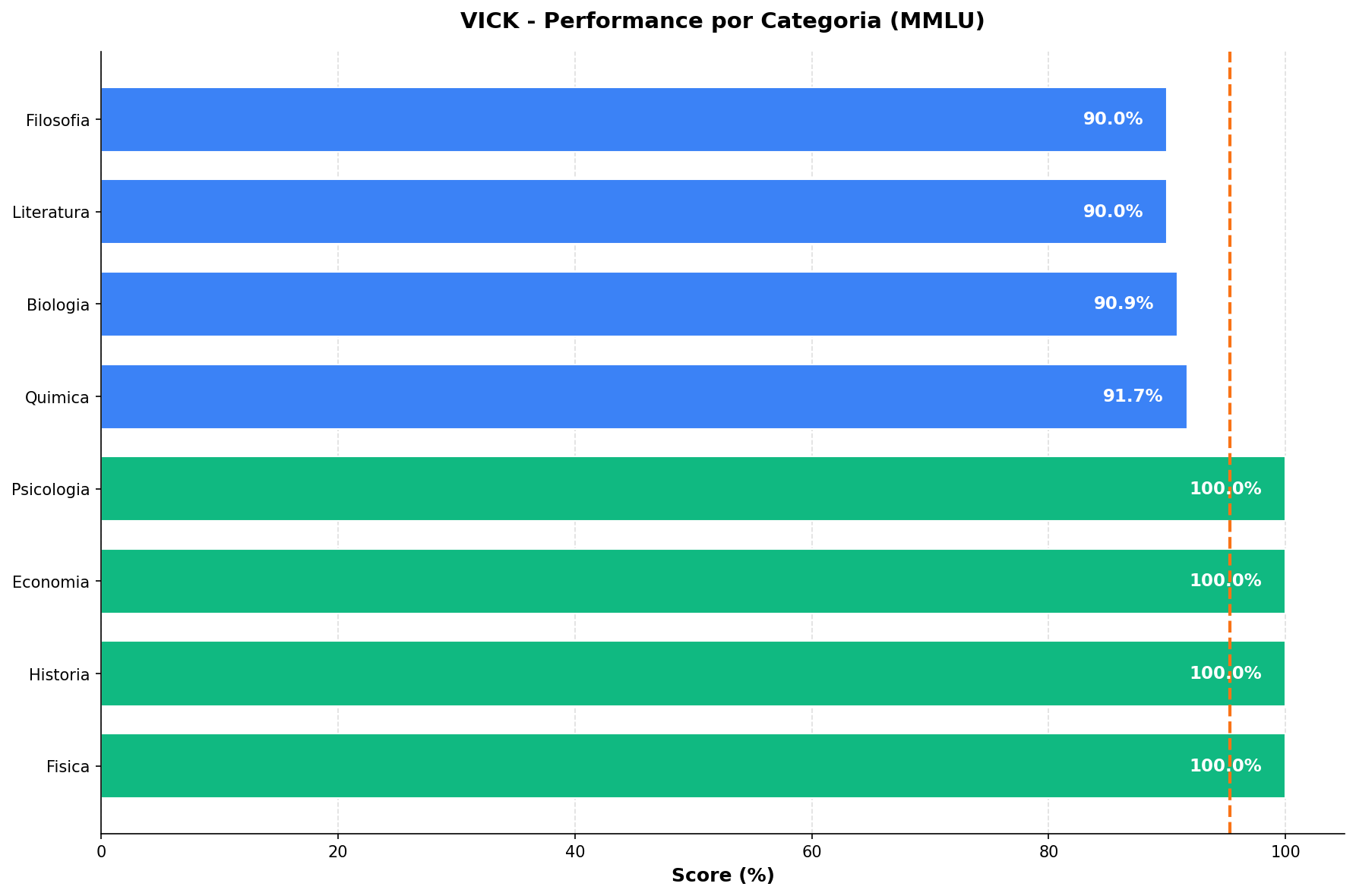
Performance por Categoria
Detalhamento do desempenho do VICK em cada categoria do MMLU.
Metodologia
Detalhes sobre como os benchmarks foram conduzidos.
Parametros do Teste
Modelos Testados
VICK Conversacional: Utilizado para o benchmark MMLU (conhecimento geral).
VICK CLI: Utilizado para HumanEval (codigo) e GSM8K (matematica).
MMLU
Perguntas de multipla escolha cobrindo 12 categorias: Matematica, Fisica, Quimica, Biologia, Historia, Literatura, Filosofia, Geografia, Economia, Psicologia, Computacao e Outros.
HumanEval
Benchmark de geracao de codigo Python. O modelo recebe a assinatura da funcao e docstring, e deve completar a implementacao corretamente.
GSM8K
Problemas de matematica em linguagem natural. O modelo deve resolver passo a passo e fornecer a resposta numerica final.
Configuracao
Temperature: 0.0 (deterministic), Max tokens variavel por benchmark, API compativel com OpenAI.
Data do Teste
12 de Janeiro de 2026. Todos os testes foram executados sequencialmente com rate limiting para garantir estabilidade.